Making an AI youtube shorts generator.

An automated youtube channel completely handled by AI.
Can Youtube Content Be AI Generated?
A few months ago, a friend messaged me about an idea he recently had: making a Youtube-Video-Shorts-Generator-3000 using AI, that would, given a few information such as a video title and a body, generate a completely modern-style short video, and automatically upload it to youtube. His goal was to start a fully automatic youtube channel, have it go viral, and eventually monetize it.
When he went up to me with this idea, I already knew he wasn't the first to think about this. In these last couple of years, with the rising of AI, I've seen tons and tons of attempts at AI generated content, and had already thought of giving it a go myself.
I decided to take this as an opportunity to actually dip my hands into this type of projects, so we hopped on a call and started brainstorming an approach to the problem. In the end, we settled for a generator that would fetch a specific pair of Post & Reply from the popular sub r/AskReddit, and generate a youtube short ready for upload.
This wasn't going to be easy.
Subscribe to my blogposts
Get updates on my latest projects and articles directly to your inbox. No spam.
How do you go from a Reddit Post to a Youtube Short?
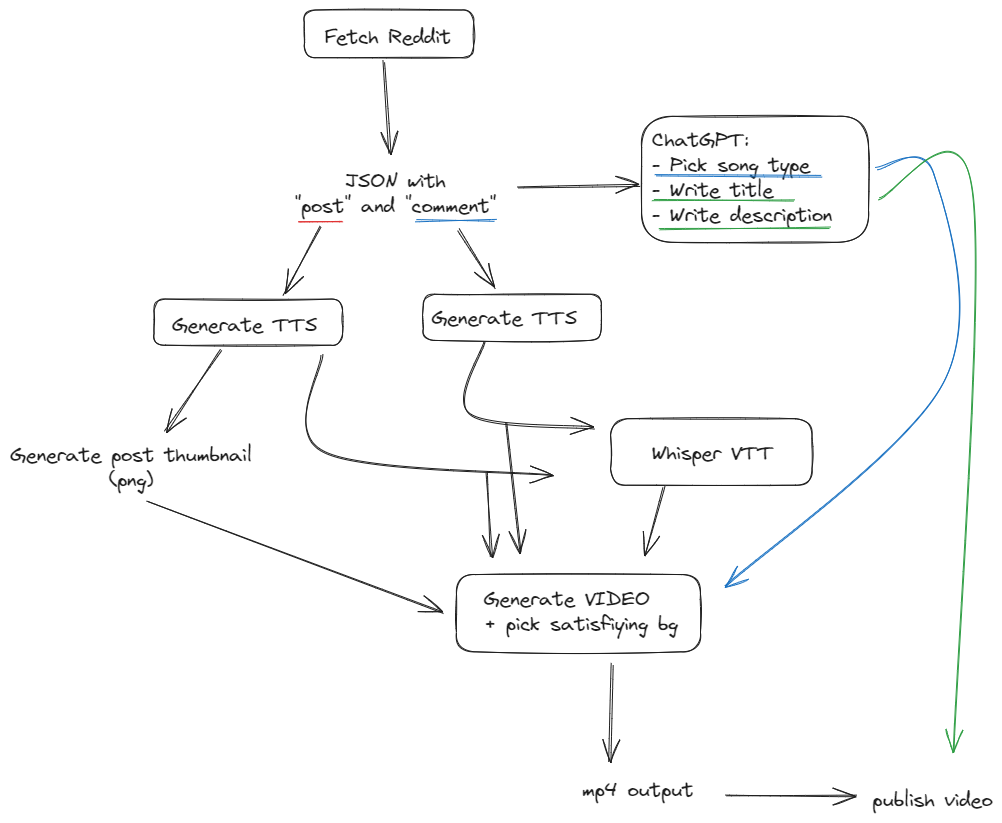 Converting from a text document to a well-edited & subtitled video is no easy task. Let's think about this problem, and break it up in single stepts that
a computer would need to do to accomplish this goal. First of all, we need to access reddit.
Converting from a text document to a well-edited & subtitled video is no easy task. Let's think about this problem, and break it up in single stepts that
a computer would need to do to accomplish this goal. First of all, we need to access reddit.
Given a link to some content, using the Reddit API, we were able to access a set of meta information about the post, such as the author, the title, the description, and even the replies. You can think about our "post" object as something like the following:
post = {
"title": None,
"sub": sub,
"selftext": None,
"author": "DereX",
"post_id": post,
"title_audio_data": None,
"selftext_audio_data": None,
"thumbnail_duration": 0.0,
"folder_name": None,
"comments": []
}
After our post object was found and retrieved, we created a thumbnail for the post. This part was handled by my friend that worked on the project with me, and basically created an image off of this POST element. Our goal was to display the thumbnail as the first part of the video, as if it was a screenshot taken off reddit and edited in the short.
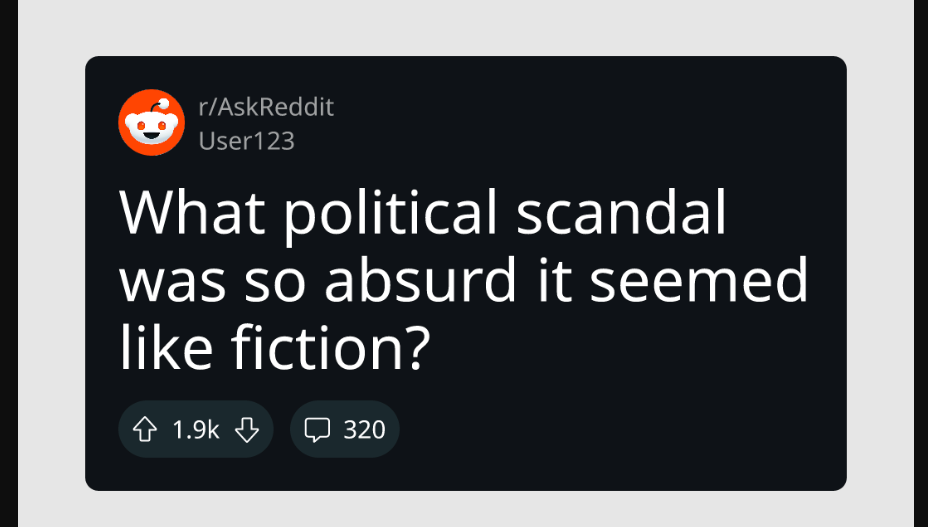
We felt that the number of upvotes & comments wasn't a really necessary detail, so we randomly generated those numbers.
How Did We Generate The Voice?
As we moved forward, the next challenge was to generate a voiceover for our video that would resonate with viewers. We aimed to mimic that distinctive TikTok female voice, which had become synonymous with viral content. Unfortunately, after scouring various TTS (Text-to-Speech) services, we realize that none offered an affordable or even remotely accurate replication of that voice.
Just when we were about to give up, I stumbled upon a website that used the exact voice we were looking for. This site exposed an API that allowed users to generate voice samples. While I'm not sure if the developer was aware of the API's potential, I decided to leverage it for our project.
As of right now, the API we used doesn't seem to work anymore
There was a catch, though: the API had limitations on the length of the text it could process in one go. To work around this, I implemented a function that intelligently split the text into smaller chunks. Each chunk was carefully crafted to stay within the maximum allowed length, ensuring that the voice generation would not be cut off abruptly. These chunks were then processed individually, and the resulting audio files were stored in a specific folder structure:
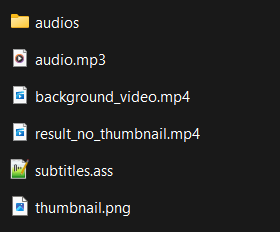
./generated/<reddit_post_id>-<unix_date>/
Within this folder, we stored both the thumbnail and the audio files.
The audio files were named sequentially, like sample1.wav, sample2.wav, and so on, to keep everything organized and easily accessible
With this setup, we could efficiently manage and retrieve the assets needed for each video.
Synchronizing Subtitles with the Voice
Once we had our audio files, the next step was to generate accurate subtitles. To achieve this, we merged all the audio samples into a single file, which allowed us to have one continuous voiceover. The key to creating engaging subtitles is precise timing, so we turned to OpenAI's Whisper model for this task. Whisper has a word-by-word mode that generates timing data for each spoken word, which was exactly what we needed.
We fed the combined audio file into Whisper, and it produced a detailed transcription along with timestamps for each word. This data was critical for the next phase of our project: creating animated subtitles.
By having exact timings, we could ensure that each word appeared on screen at the perfect moment, enhancing the overall viewer experience and making the video more dynamic.
Ensuring Audio Length and Segmenting for Whisper
Thanks to the calculations we performed earlier, we were confident that the audio length stayed within the API's limits.
Moreover, we noticed that OpenAI's Whisper model, which we would use for Text Timing Generation, was more effective with short segments of words rather than a long single audio file.
To begin, we looped through the segments that made up the TITLE. For each audio segment, we calculated its length and summed them to determine the value for post["thumbnail_duration"].
Then, we transcribed each segment into a subtitles file using the Whisper API.
Whisper provides a function that generates transcriptions word by word, giving us precise timings for the spoken text.
However, the challenge was that each timing was relative to the start of each individual segment. Each segment consists of words in a format like this:
{
"task": "transcribe",
"language": "english",
"duration": 8.470000267028809,
"text": "The beach was a popular spot on a hot summer day. People were swimming in the ocean, building sandcastles, and playing beach volleyball.",
"segments": [
{
"id": 0,
"seek": 0,
"start": 0.0,
"end": 3.319999933242798,
"text": "The beach was a popular spot on a hot summer day."
...
},
...
]
}
As shown above, each word group has a start and end value. With multiple audio segments, we needed to create a function that would offset each word group to its correct position within the entire audio duration, accounting for the segments that preceded it.
Generating Subtitles with Procedural Animations
Now that we had a detailed JSON of all this information, the next step was to generate subtitles. Instead of adding standard subtitles, we wanted to incorporate procedural animations.
To achieve this, I decided to use a file format called "ASS" (SubStation Alpha). This format allows for animations in each subtitle line based on timestamps, and it can be read by FFMPEG to render these subtitles onto the video.
The ASS format consists of a header, where the subtitle styles are defined, followed by a list of subtitle lines. I pre-constructed the header, which will be inserted later.
[Script Info]
PlayResY: 600
WrapStyle: 1
[V4+ Styles]
Format: Name, Fontname, Fontsize, PrimaryColour, SecondaryColour, OutlineColour, BackColour, Bold, Italic, Underline, StrikeOut, ScaleX, ScaleY, Spacing, Angle, BorderStyle, Outline, Shadow, Alignment, MarginL, MarginR, MarginV, Encoding
Style: en_us_001, Dosis-Bold,30,&H00FFFFFF,&H00FFFFFF,&H00303030,&H80000008,0,0,0,0,100,100,0,0,1,1,1,2,10,10,300,1
Style: en_us_006, Dosis-Bold,30,&H00BBFAC5,&H00FFFFFF,&H00303030,&H80000008,0,0,0,0,100,100,0,0,1,1,1,2,10,10,300,1
Style: en_us_007, Dosis-Bold,30,&H00BBCFFA,&H00FFFFFF,&H00303030,&H80000008,0,0,0,0,100,100,0,0,1,1,1,2,10,10,300,1
Style: en_us_009, Dosis-Bold,30,&H00F7BBFA,&H00FFFFFF,&H00303030,&H80000008,0,0,0,0,100,100,0,0,1,1,1,2,10,10,300,1
Style: en_us_008, Dosis-Bold,30,&H00FAF6BB,&H00FFFFFF,&H00303030,&H80000008,0,0,0,0,100,100,0,0,1,1,1,2,10,10,300,1
Style: en_us_002, Dosis-Bold,30,&H00D4F6FA,&H00FFFFFF,&H00303030,&H80000008,0,0,0,0,100,100,0,0,1,1,1,2,10,10,300,1
[Events]
Format: Layer, Start, End, Style, Name, MarginL, MarginR, MarginV, Effect, Text
In the style definition, you'll notice there are multiple variants with different colors and names. This assured that based on the voice that was going to read the text, we had a different subtitle color. This is really important for the clarity of the video, and add some variation to it.
Here’s a glimpse of our ConvertToAss function. This function iterates through the verbose_json generated by Whisper earlier, processing each word group.
It calculates variables like the grow and shrink time for each subtitle based on the word duration, determines the start and end times, and formats everything into the ASS structure.
The result is a file ready to be read by FFMPEG.
def convert_to_ass(words, folder):
content = ass_header
for i, word in enumerate(words):
word_duration = word["end"] - word["start"]
grow_time = (word_duration / 6) * 1000
shrink_time = (word_duration / 12) * 1000
start = format_time(word["start"])
end = format_time(word["end"])
voice = word["voice"]
word = word["word"]
content += f"Dialogue: 0,{start},{end},{voice},,0,0,0,," + "{" + f"\\fscx20\\fscy20\\t(0,{grow_time},\\fscx120\\fscy120)\\t({grow_time},{shrink_time},\\fscx100\\fscy100)\\t({grow_time + shrink_time},{word_duration * 1000 - shrink_time},\\fscx100\\fscy100)" + "}" + f"{word}\n"
audio_duration = words[-1]["end"] + end_padding
subs = open(f"./{folder}/subtitles.ass", "w", encoding="utf-8")
subs.write(content)
subs.close
return
The resulting file is something like this:
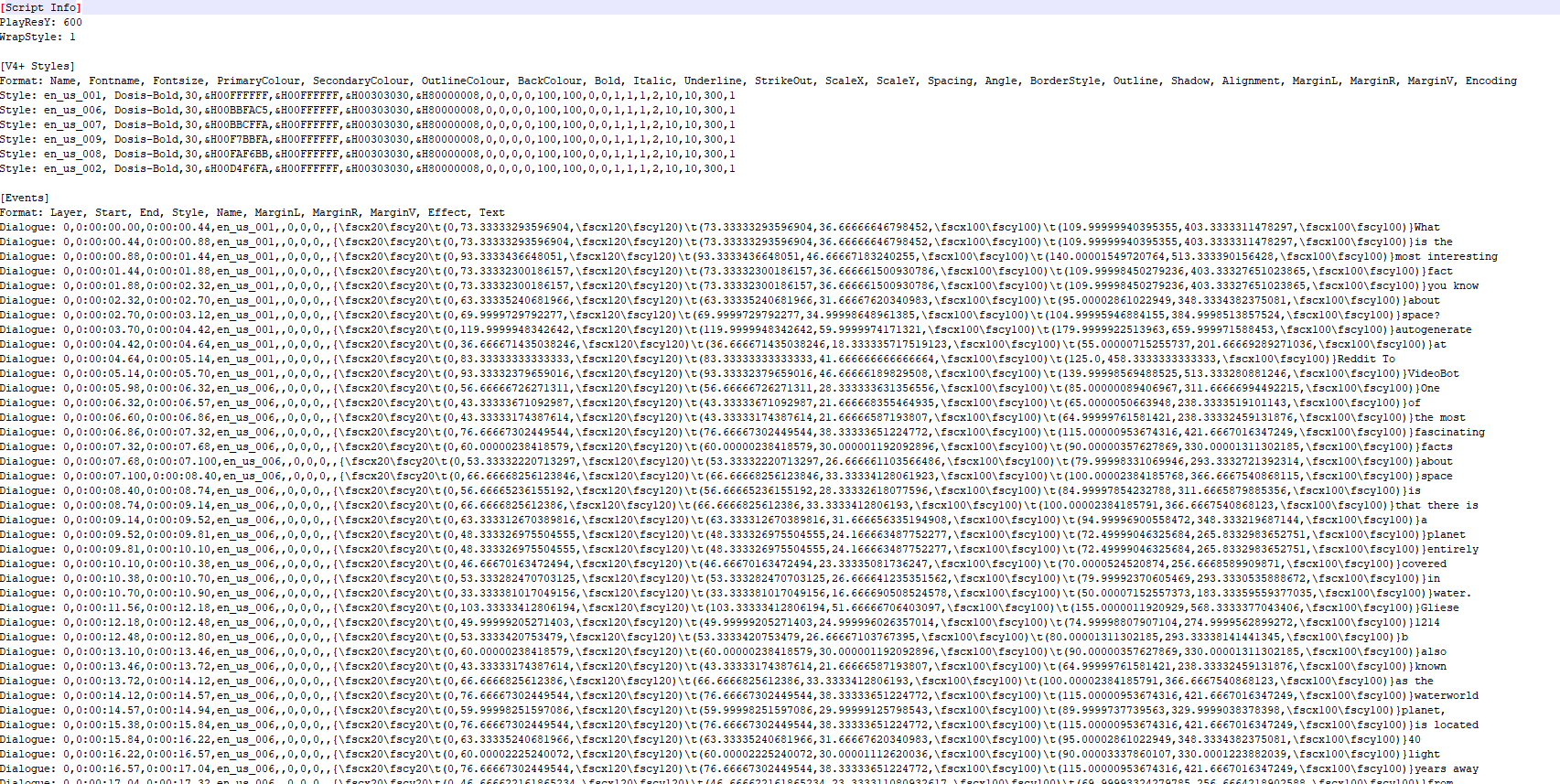
Putting It All Together
With the audio and subtitle file prepared, we used a specific function within FFMPEG to merge them, resulting in a video with synchronized audio and animated subtitles.
For the background, we selected pre-existing videos that are known to go viral on platforms like TikTok—things like GTA 5 ramps or races, Minecraft parkour, pressure washing, or bike downhill riding. These types of content are engaging yet non-distracting, keeping the viewer's eyes focused on the video.
It's worth mentioning that our transcription file also generates audio for the title of the subreddit post. However, since we already created a thumbnail for this purpose, we simply overlayed the thumbnail image at the start of the video to display the title, then faded it out when the main reply began.
Finally, we added some generic background music, and that was it! We successfully built a generator that starts with a Reddit post, generates corresponding audio, transcribes the audio with precise timings, creates animated subtitles using ASS, and merges everything with a random background video and audio using FFMPEG.
Expanding the Project: Moving to Telegram
After we finished the initial bot, I realized I wasn't quite satisfied and wanted to take it a step further by moving the entire interface to a Telegram bot.
I developed a bot that monitored any links sent in a specific chat. For each link, the bot would prompt the user to choose the type of video they wanted to generate: Comment, Post, or Post with Top Comments. Here’s how each option worked:
Comment: If the link pointed to a comment, the bot would generate the post title along with the subtitled comment, as described earlier.
Post: This option generated the post's title, created a thumbnail, and subtitled the post's selftext. This was particularly useful for posts where the author narrated a story or where the post itself was the focal point.
Post & Top Comments: The bot would generate the title and thumbnail, then loop through the top comments. It would ask ChatGPT to rate each comment in terms of length, interest, and relevance, selecting the best three or four. The bot would then concatenate different voices, each with distinct subtitle colors, to read these texts sequentially.
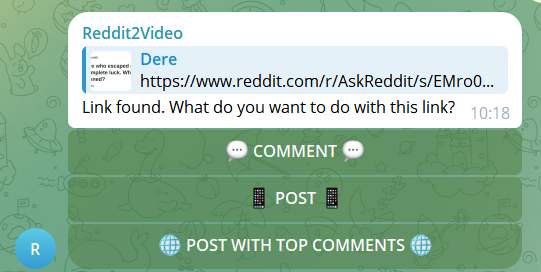
Interestingly, the "Post" feature became our most used. We found it to be the most effective, as the "Post & Top Comments" option sometimes produced videos that were too long for YouTube Shorts. Additionally, it could be difficult to distinguish when one comment ended and another began, making the video less engaging.
Automation and Review Process
Once a post was selected, the bot ran the entire process from start to finish, then sent the video back to us on Telegram in a designated pending-videos channel. This allowed us to review the generated videos and manually decide if they were good enough for upload. We could approve or reject each video. If a video was rejected, it would be deleted. Approved videos were sent to a queue folder, which would then be processed for automatic YouTube upload.
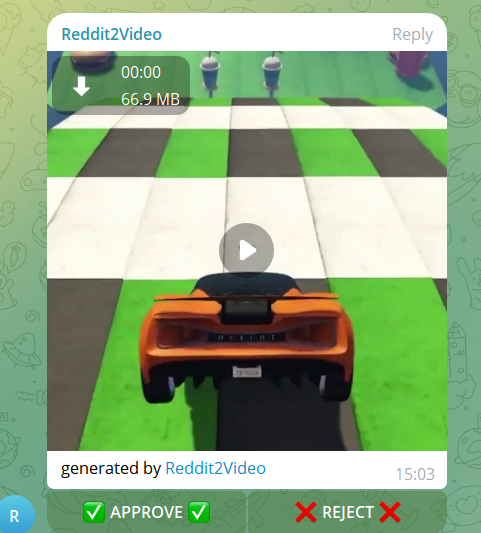
I’ll dive into the details of automatic YouTube uploads via Selenium in another post, but suffice to say, it was one of the hardest parts of the project. I wasn’t expecting it to be so challenging, and I had to resort to using a domestic IP address and multiple Selenium attempts to successfully access a YouTube channel and upload a video with specific metadata.
Finally, we set up an "uploaded-videos" channel to notify us of every single upload on the YouTube channel, along with how many videos were left in the queue.
The Hardcode Feature and Exploring New Possibilities
Not one to stop there, I added a feature that allowed us to "Hard Code" posts. This enabled us to generate videos not based on a Reddit link, but on a custom set of author, subreddit, title, and selftext combinations. For example, a command could look like this:
/hardcode AskReddit|Redditors, what is the scariest experience you have ever had?|Wake up. Wake up. Wake up. Wake up. Wake up. Stop scrolling YouTube Shorts. Stop scrolling YouTube Shorts. Wake up. Wake up. Make something productive with your time. Stop the brainrot. Stop the brainrot. Wake up. Wake up. Wake up.
I even explored the idea of using this feature for advertising. I could craft stories that promoted a brand, as in this example where I created a "fake" post to promote a friend’s Formula 1-themed clothing brand:
/hardcode formula1|Redditors, what is the best gift for a F1 Fan?|Recently, I found a really underrated brand called FLF Design. As you probably know, Formula 1 doesn't have any minimalistic clothing line, but only jackets filled with sponsors and names. As a minimalistic lover, the FLF Designs are fire. They basically turn the sport we all love and the racing cars into neat art for your clothes, which is something I rarely see around. If someone I know is reading this, please gift me this brand!
Autogenerate: Full Automation
The last twist I added to the Telegram bot was an /autogenerate command, which fully automated the video creation process. I could generate posts and captions using ChatGPT and then paste them into my /hardcode command, but I wanted to eliminate even those steps. The /autogenerate command took care of everything:
COMMAND:
/autogenerate (no prompt)
Sub: AskReddit
Title: What's the most unusual task you've been assigned at work?
Author: Dere
Comment: I once worked at a marketing firm and was asked to dress up as a giant sandwich and hand out flyers on the street.
I was initially hesitant, but my boss assured me it was a great way to attract attention.
Surprisingly, it ended up being a lot of fun and people loved taking pictures with 'the walking sandwich'.
It was definitely a memorable experience and a unique way to promote our client's sandwich shop.
COMMAND:
/autogenerate What is the most offensive thing you've heard from a teacher?
Sub: AskReddit
Title: What is the most offensive thing you've heard from a teacher?
Author: Dere
Comment: I once had a teacher in high school who told me in front of the entire class that
I would never amount to anything because of my learning disability.
It was absolutely crushing to hear those words from someone who was supposed to encourage and support me.
However, I used that negativity as fuel to prove them wrong.
Years later, I not only graduated college but also started my own successful business.
Sometimes, the most hurtful words can be the biggest motivation to succeed.
While these auto-generated stories were not always the most original or interesting, and thus the feature wasn’t used extensively, it still added a layer of automation that could be handy in specific scenarios.
Conclusions and going forward
After we finished developing the bot, we put it online on a server and used it consistently for a couple of months. The bot was uploading content on a 6-hour basis, and we were constantly generating new videos for it. You can find the videos in the Shorts section of this YouTube channel: @DereDev. Some videos even went "a little bit" viral, reaching up to 7,200 views, like this one.
This particular video is noteworthy because it's the first ever video we generated and uploaded using the Telegram workflow—from start to finish—and it immediately got pushed by the algorithm. You can imagine how thrilled I was to see everything work and actually perform as expected on YouTube.
However, after those couple of months, we stopped generating videos. Fewer and fewer were being picked up by the algorithm, and our focus started shifting to new projects. Additionally, we didn’t have Shorts Monetization enabled, so we weren’t earning back our expenses in OpenAI credits. What remains is an archive of AI-generated videos on that channel and a wealth of experience from the topics I discussed in this post.
I hope you found this journey interesting! Thanks for reading, and feel free to check out my other blog posts—I have plenty of similar projects that I think you'll enjoy.