How I Built an AI-Generated Show

A behind-the-scenes look at how I built an AI-generated livestream using Unity, GPT, and TTS to simulate Spongebob characters in surreal, user-driven episodes.
At the end of my first year in university, I remember opening YouTube and spotting a really strange livestream on the homepage.
It featured AI-generated Spongebob episodes; so obviously, I clicked on it.
The livestream was... surreal. It was a kind of simulation where Spongebob characters moved around a 3D environment, enacting conversations using AI-generated voices and scripts.
What stood out even more was the chat. It was constantly interacting with the stream, even suggesting new topics for episodes.
An episode was essentially a short scene, max 1 minute long, where characters discussed a topic in a humorous or completely unhinged way.
The AI left plenty of amusing artifacts: glitchy, unnatural voice breaks and absurd, chaotic dialogue that added to the charm.
I knew I had to make my own version of it.
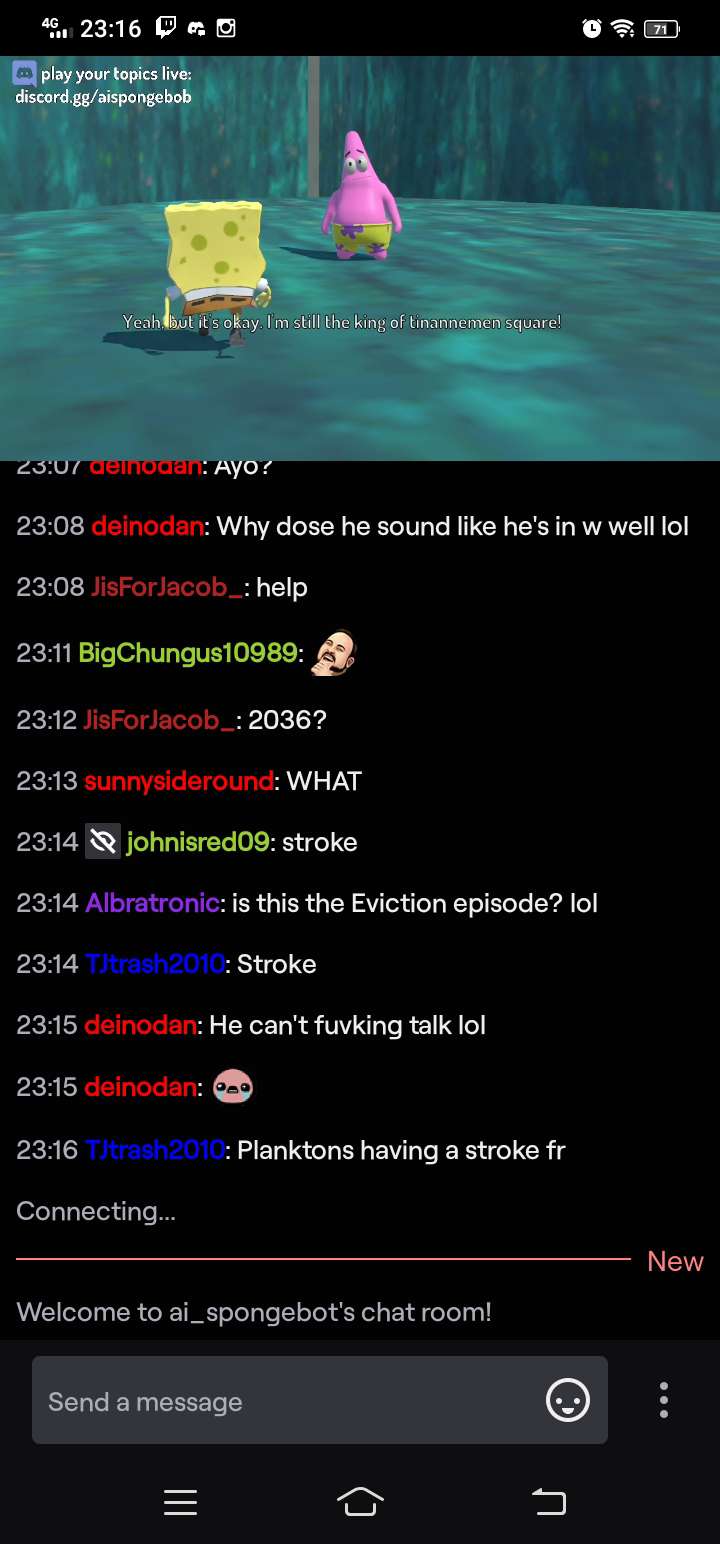
A screenshot of the live chat from when my project was running
Subscribe to my blogposts
Get updates on my latest projects and articles directly to your inbox. No spam.
Designing the System
Watching the livestream, I quickly pictured how it worked.
There were multiple parts at play: a backend generating scripts with text and voice, a frontend simulating those scripts in a scene, and AI powering the whole process. Conversations were pre-generated in the background since they couldn’t be done live, then the frontend looped through them to recreate the broadcast.
It wasn’t simple, but that was the core idea. Let's cover the parts step by step.

The Heart of the Project
I called the core module the Generator, because it created .json files for each conversation.
Scene Metadata
The process worked in a loop. It would:
- Pick a random topic from a list
- Randomly select 2–3 characters from a pool of 8
- Choose a location and a transition
The location was a spot in a simple 3D model of Bikini Bottom, which I pulled from a sketchy Spongebob 3D fan-game site. The transition was a Spongebob-style scene change (e.g., “X hours later…”).
These metadata elements shaped the scene: from which characters would appear, to what location would be shown, and even which type of transition effect to use.
The Conversation
After selecting a topic, the Python script would call the OpenAI API to generate a conversation object.
It also passed in contextual data. I wanted the simulation to feel self-aware: characters would reference previous scenes or recognize their current location. This made the whole thing feel more “alive”, as if the characters had continuity, memory, and evolving personalities.
Each conversation entry followed this structure:
{
"role": "Spongebob",
"text": "Hey Patrick, have you seen Sandy around today?",
"uuid": "d5b4980b-8fca-493e-b6ea-0ee5697040ae",
"link": "https://uberduck-audio-outputs.s3-us-west-2.amazonaws.com/d5b4980b-8fca-493e-b6ea-0ee5697040ae/audio.wav"
}
Everything here is pretty self-explanatory. The final field, link, points to
the generated voice file.
Generating Voices
This was the most crucial part of the entire project.
Voice generation services were either too slow, low-quality, or paywalled. At the time, the most popular tool was UberDuck. (It is now mostly defunct due to the removal of character voices.)
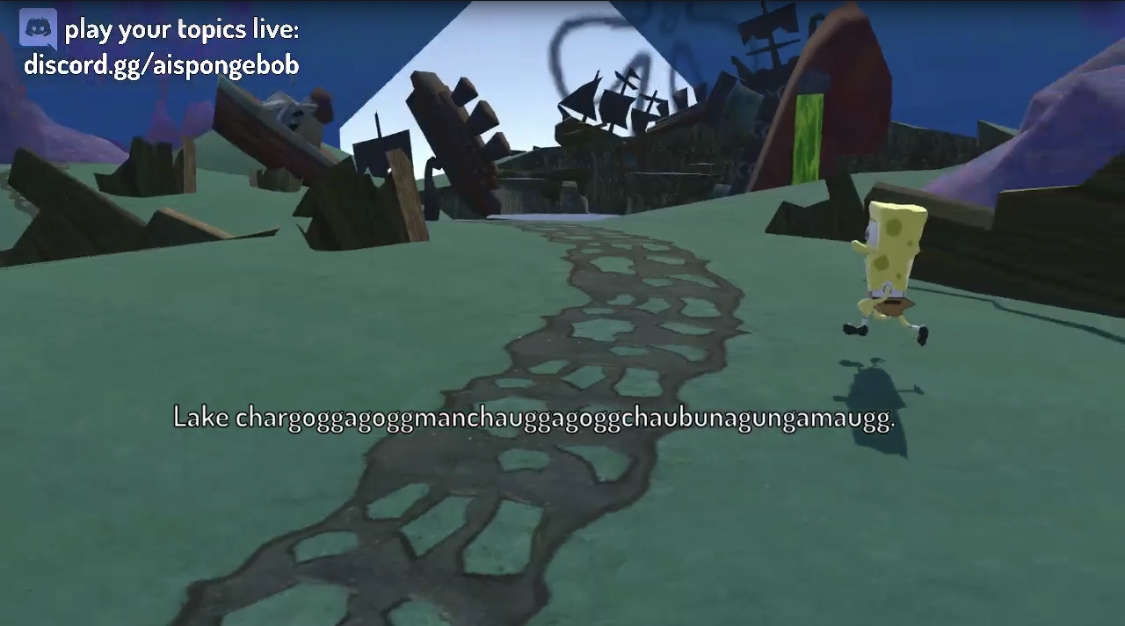
You can imagine the artifacts from AI trying to read this.
Here’s where I got lucky: UberDuck had just introduced a “paid” plan, which limited new users to a small number of voice generations.
But somehow, my account had infinite credits. I’d played around with the service before the credit system was introduced, and my account must have ended up in some kind of legacy state.
Even when my credit count dropped into the negatives, I could still generate voices with no restrictions. I kept quiet about this, I didn’t want the bug getting patched. But now that the project is inactive, I’m happy to share the story.
UberDuck returned the audio URL at the start of the request, even before the file was fully generated. So I could store the URL in the .json and immediately move on to the next dialogue line.
Simulating the Conversations
With a constant stream of conversation files being generated and dropped into a folder (yes, I should’ve used a database, but I was just experimenting), I now needed to build the simulator.
I created a Unity scene and imported:
- A 3D map of Bikini Bottom
- 3D models for all characters
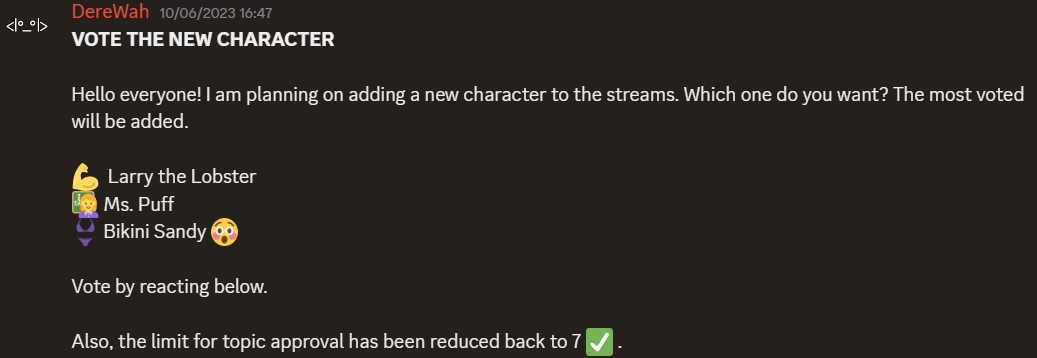
When it was time to add new characters, we made polls to let the community decide
(I won’t go into detail, but rigging, animating, and setting up new characters was one of the more labor-intensive parts.)
Each scene followed these steps:
- Load the latest conversation from the folder
- Read the
locationand place the camera accordingly - Spawn the selected characters in front of the camera
- Set the camera to follow the first character speaking
- Stream and play the dialogue audio via the URL
- Display subtitles
- Move to the next line
After the scene finished, the file was moved into a simulated folder.
This was crucial. During downtimes (e.g., for maintenance or API issues), the simulator could fall back to a random file from the simulated folder and keep the livestream going.
Running the Livestream
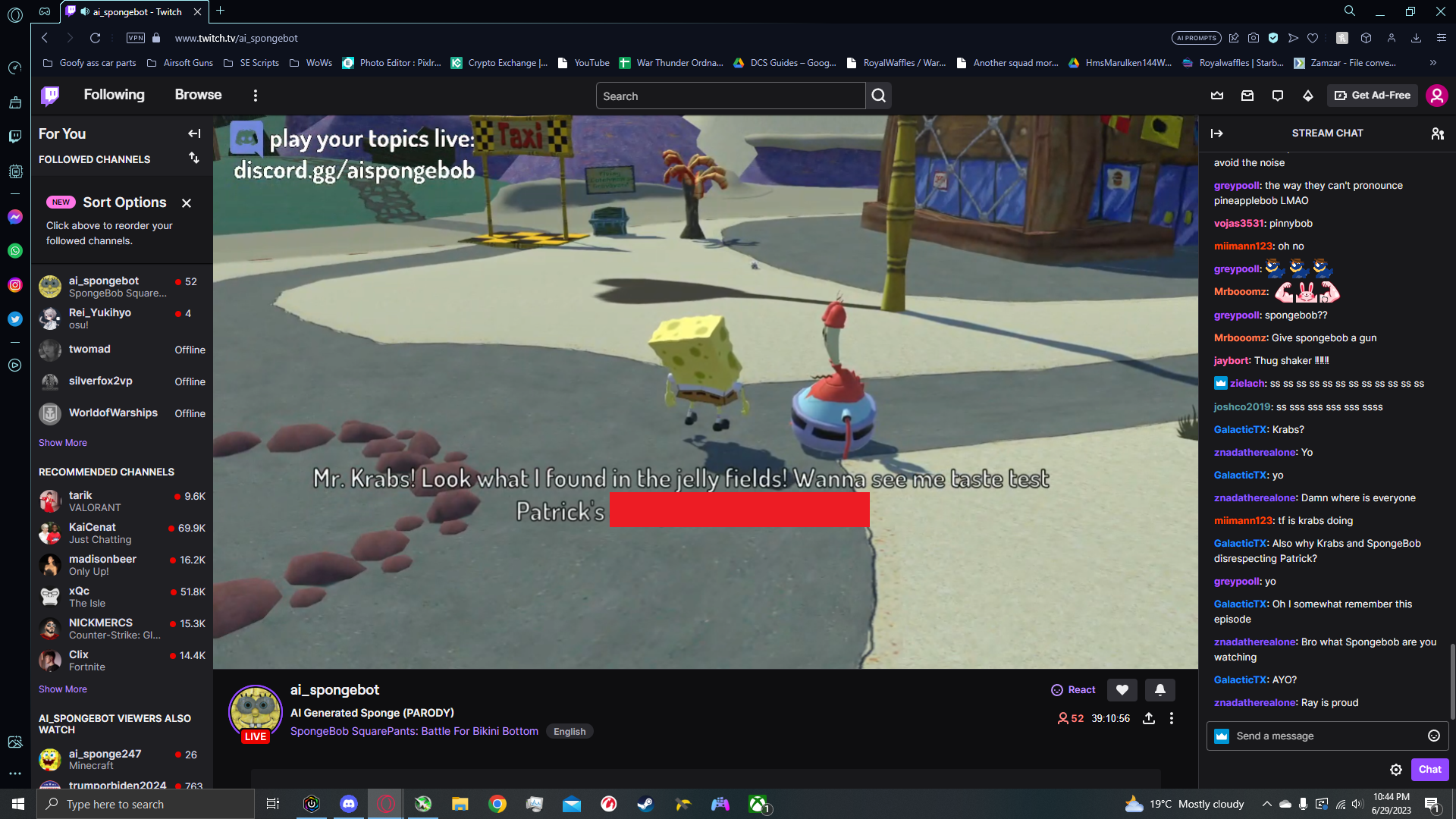
An old screenshot from when the project was running on twitch
With everything in place, I ran the setup on my computer 24/7 and launched the YouTube livestream.
I was among the first to follow up on the trend, so my version gained decent traction. While it didn’t reach the numbers of the original, I built a small, engaged community around it.
Adding some Easter Eggs
If anyone knows me, they also know I love breaking the 4th wall. Anything that winks to the user, and becomes at any point self-aware, makes me really appreciate the self-irony of the people behind it.
I couldn't miss this opportunity to atleast do something.
The narrator voice was absolutely hilarious. It often cracked, stimmed, or just screamed, out of nowhere. It was probably something up with the accent and the low quality of the model, and it was unsettling.
So I ended up generating some voice lines for the transitions saying wild stuff, such as the virtual narrator saying "Please Help Me", or "Make It Stop", as if he was being forced to work for the show.
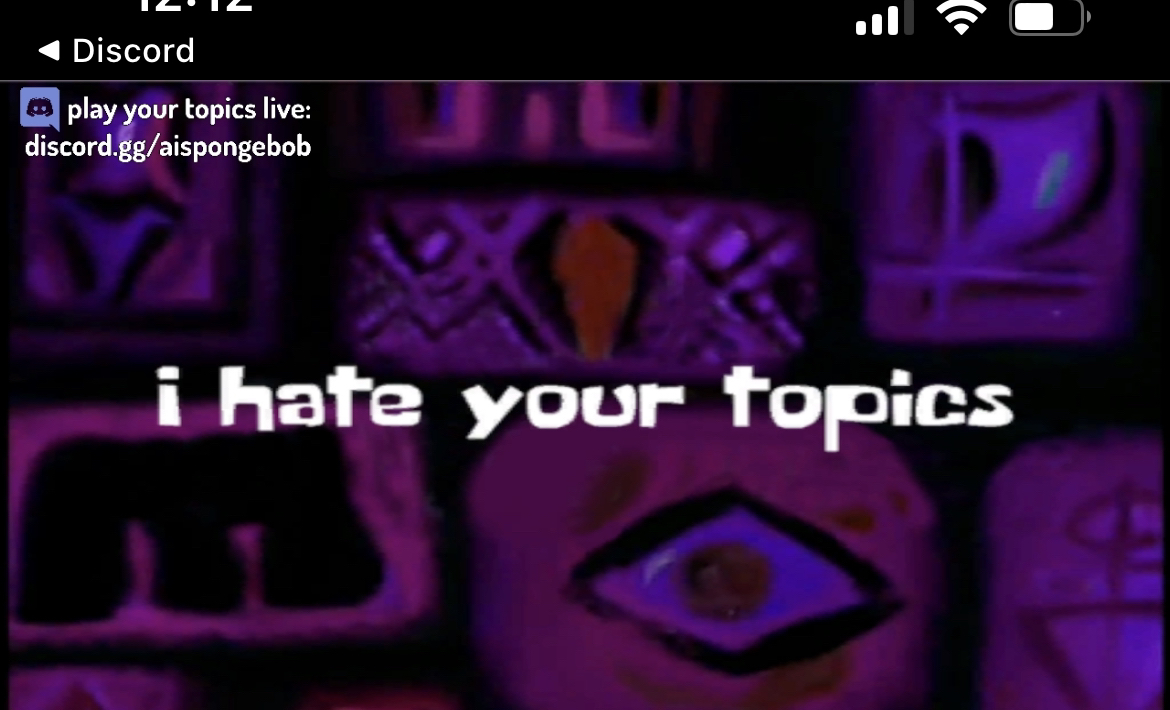
Some other transition lines were just the narrator not saying anything, or at other points just full AI artifacts sounds from the model.

Enabling Viewer Interactions
Interactivity was a major goal. I wanted users to be able to suggest new topics in real time, making the stream feel alive and giving viewers a reason to stay or share.
Also, API usage wasn’t cheap, so I created a simple business model to cover costs. And to my surprise... it worked very well for a side project!
Free Plan
- New Discord users received 3 free topic suggestions
- Topics were submitted via the
#suggest-topicschannel - Suggestions weren’t processed immediately: they went up for a vote
- Users could upvote/downvote suggestions with emoji reactions
- Once a suggestion received 10 green votes, it was added to the generation queue
This acted as a kind of crowd-sourced moderation system. It wasn’t perfect, but it filtered out most problematic suggestions.
Donators
Since voting meant your topic might never get picked, I introduced a paid plan.
For $5, users could submit unlimited topic suggestions, basically skipping the 3/day limit.
Even donator suggestions still had to go through the public vote, but the low price and quick turnaround (within ~10 minutes) made it worthwhile.
I used a Tebex shop with a custom discord bot to manage purchases and submissions. I’d used Tebex in past projects, and it worked reliably while giving users a familiar interface.
Improving the Project
As the project gained traction, I rolled out small updates:
- Added new characters and locations
- Improved the overall scene flow
- Tweaked internal systems
Honestly, the codebase was held together with duct tape. When I started, I had no clue what the final system would look like, but it’s all part of learning. You build messy things first, and then, eventually, you learn how to recognize the mess and improve it.
It's not about doing everything perfectly: it's about improving bit by bit until you can look back and say, “Yeah, that was rough... but I learned a lot.”
Eventually, the hype faded. Spongebob rights holders started cracking down. TTS services began restricting access or removing copyrighted voice models. UberDuck, in particular, removed all unlicensed voices... basically 99% of its library.
Final Thoughts
This was a passion project that brought me into contact with many amazing people, including my close friend Giovanni, who was working on a similar idea at the time.
He even wrote a blog post about his experience with AI-generated shows. If you're curious, check it out!
It was weird, chaotic, hilarious, and an incredible learning experience.